Java 为了满足跨平台的需求,将 Java 代码首先编译成平台无关的字节码,然后通过 JVM 解释执行。同时,为了尽可能的提高性能引入了即时编译(JIT),会在代码运行时分析热点代码片段将其编译为字节码执行。原理我能讲出来,但是细节方面我就说不出来了。这次我以一个注解为入口,看看 JDK 源码来了解一下 Java 即时编译的简单原理。
HotSpotIntrinsicCandidate 注解
之前我在看 Netty 内存分配逻辑的时候,发现 Netty 分配内存并没有使用 new 关键字,而是使用了下面这个方法:
@HotSpotIntrinsicCandidate
private Object allocateUninitializedArray0(Class<?> componentType, int length) {
// These fallbacks provide zeroed arrays, but intrinsic is not required to
// return the zeroed arrays. if (componentType == byte.class) return new byte[length];
if (componentType == boolean.class) return new boolean[length];
if (componentType == short.class) return new short[length];
if (componentType == char.class) return new char[length];
if (componentType == int.class) return new int[length];
if (componentType == float.class) return new float[length];
if (componentType == long.class) return new long[length];
if (componentType == double.class) return new double[length];
return null;
}
这块代码带了@HotSpotIntrinsicCandidate 注解(这个注解在 JDK16 之后变成了@IntrinsicCandidate),它实际上会尝试调用 HotSpot JVM 的内化的(intrinsified)实现来提高性能,可能是手写汇编代码或者手写中级表示(Intermediate Representation)代码(C++)。
这里其实跟 JNI(Java Native Interface,对于 native 方法)有一些像,只不过 JNI 是固定调用 C++代码,而这个注解是动态调用 C++中间代码,相当于优化了 JVM 和 native 代码之间的联系,让代码更快。这可能也是为什么很多方法既是 native,也带 intrinsic 注解的原因吧。
分层编译
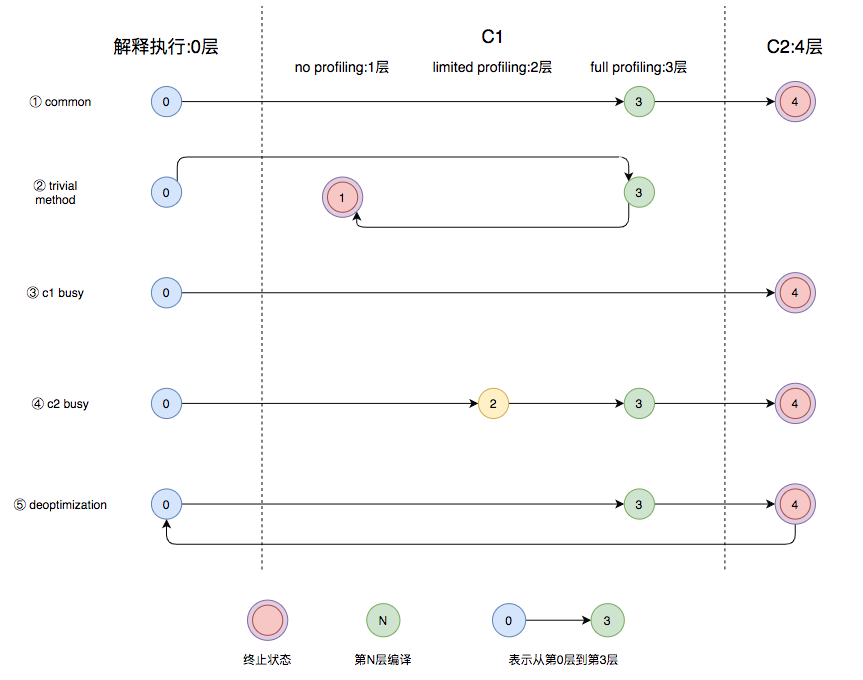
从 JDK7 开始,Java 支持分层编译。关于分层编译的定义,可以参考源码compilationPolicy.hpp的注释,写的非常清楚,截取一段对于层级的定义如下:
The system supports 5 execution levels:
level 0 - interpreter
level 1 - C1 with full optimization (no profiling)
level 2 - C1 with invocation and backedge counters
level 3 - C1 with full profiling (level 2 + MDO)
level 4 - C2
看起来很复杂,有五个层级,其实理解起来很简单:
- 执行速度上:0 < 1 < 4,2 比 1 慢,3 比 2 慢(因为需要记录一些信息)
- 编译时间上:0 < 1 < 4,2 和 3 与 1 相同
- JDK 会根据 C1 和 C2 编译器的排队情况和 C1 或者解释器执行的统计值决定下一个状态是什么,正常情况下都是从 0 最终到 4,但在优化过于激进的情况下可能会回退状态(比如 C2 速度和 C1 相同的情况)。
这里借用一下美团技术团队的状态流转图:
看源码
回到最开始的问题,我很想知道为什么 Netty 要选用加上@HotSpotIntrinsicCandidate 注解的代码,它为什么会比 new 还快。 首先,所有的@HotSpotIntrinsicCandidate 注解定义都在 vmIntrinsics.hpp 中
do_intrinsic(_allocateUninitializedArray, jdk_internal_misc_Unsafe, allocateUninitializedArray_name, newArray_signature, F_R)
do_name( allocateUninitializedArray_name, "allocateUninitializedArray0")
需要注意的是,这里仅仅做了定义,将 Java 代码中的 allocateUninitializedArray0 方法绑定了 C++的_allocateUninitializedArray 方法,方法实际定义在 library_call.cpp 中:
case vmIntrinsics::_allocateUninitializedArray: return inline_unsafe_newArray(true);
这里 library_call.cpp 中定义的方法是 C2 编译优化使用的,我没有在 JDK 源码中找到 allocateUninitializedArray0 对应的 C1 源码,说明 C1 应该是根据 Java 方法默认的定义来优化的。
这里指向了这个方法 inline_unsafe_newArray,源码如下:
//-----------------------inline_native_newArray--------------------------
// private static native Object java.lang.reflect.newArray(Class<?> componentType, int length);
// private native Object Unsafe.allocateUninitializedArray0(Class<?> cls, int size);
bool LibraryCallKit::inline_unsafe_newArray(bool uninitialized) {
Node* mirror;
Node* count_val;
// 读取入参,一个是数组元素类型,一个是数组元素数量
if (uninitialized) {
mirror = argument(1);
count_val = argument(2);
} else {
mirror = argument(0);
count_val = argument(1);
}
mirror = null_check(mirror);
// If mirror or obj is dead, only null-path is taken.
if (stopped()) return true;
// 定义了两种路径,slow_path对应第一阶段(字节码解释),normal_path对应第五阶段(C2编译优化)
enum { _normal_path = 1, _slow_path = 2, PATH_LIMIT };
// 定义了C2的图(Ideal Graph)
RegionNode* result_reg = new RegionNode(PATH_LIMIT);
PhiNode* result_val = new PhiNode(result_reg, TypeInstPtr::NOTNULL);
PhiNode* result_io = new PhiNode(result_reg, Type::ABIO);
PhiNode* result_mem = new PhiNode(result_reg, Type::MEMORY, TypePtr::BOTTOM);
bool never_see_null = !too_many_traps(Deoptimization::Reason_null_check);
Node* klass_node = load_array_klass_from_mirror(mirror, never_see_null,
result_reg, _slow_path);
Node* normal_ctl = control();
Node* no_array_ctl = result_reg->in(_slow_path);
// Generate code for the slow case. We make a call to newArray().
// 字节码解释执行的逻辑,实际上就会调用定义在allocateUninitializedArray0中的默认实现
set_control(no_array_ctl);
if (!stopped()) {
// Either the input type is void.class, or else the
// array klass has not yet been cached. Either the // ensuing call will throw an exception, or else it // will cache the array klass for next time. PreserveJVMState pjvms(this);
CallJavaNode* slow_call = NULL;
if (uninitialized) {
// Generate optimized virtual call (holder class 'Unsafe' is final)
slow_call = generate_method_call(vmIntrinsics::_allocateUninitializedArray, false, false);
} else {
slow_call = generate_method_call_static(vmIntrinsics::_newArray);
}
Node* slow_result = set_results_for_java_call(slow_call);
// this->control() comes from set_results_for_java_call
result_reg->set_req(_slow_path, control());
result_val->set_req(_slow_path, slow_result);
result_io ->set_req(_slow_path, i_o());
result_mem->set_req(_slow_path, reset_memory());
}
set_control(normal_ctl);
// C2编译优化的逻辑
if (!stopped()) {
// Normal case: The array type has been cached in the java.lang.Class.
// The following call works fine even if the array type is polymorphic. // It could be a dynamic mix of int[], boolean[], Object[], etc.
// new_array是具体allocate逻辑
Node* obj = new_array(klass_node, count_val, 0); // no arguments to push
result_reg->init_req(_normal_path, control());
result_val->init_req(_normal_path, obj);
result_io ->init_req(_normal_path, i_o());
result_mem->init_req(_normal_path, reset_memory());
if (uninitialized) {
// Mark the allocation so that zeroing is skipped
// 这里注释很重要,分配内存的置零被跳过了
AllocateArrayNode* alloc = AllocateArrayNode::Ideal_array_allocation(obj, &_gvn);
alloc->maybe_set_complete(&_gvn);
}
}
// Return the combined state.
set_i_o( _gvn.transform(result_io) );
set_all_memory( _gvn.transform(result_mem));
C->set_has_split_ifs(true); // Has chance for split-if optimization
set_result(result_reg, result_val);
return true;
}
结合注释可以看出来,allocateUninitializedArray0 除了 C2 本身的优化之外,还跳过了分配内存的置零阶段。这也符合 Java 源码里面 allocateUninitializedArray0 的注释:
Allocates an array of a given type, but does not do zeroing.
对于 new 关键字初始化的数组来说,我们知道,JVM 会置零这个数组:
byte[] bytes = new byte[10];
// bytes数组的每一个元素都是0x00
实际上,置零这个操作耗时还是挺长的(可以参考 stackoverflow 的问题Why is memset slow),毕竟相当于一次完整的写入。当然对于分配完数组就写入的情况来说,可能 TLB 能命中一部分,不至于差距太大。因此源码注释中也提到,只有高性能的场景才需要将 new 替换掉。并且,使用这个方法需要自己管理好引用和 GC。
当然,对于视性能如命的 Netty 来说,只要能提升性能,这些都是小问题。
总结
这次“浅入”JDK 源码,原理部分看懂的不多,但是即时编译的流程了解了一些,也明白了为什么 Netty 要用带有即时编译优化的 Unsafe 方法替换掉 new。希望以后还有机会去真正深入看看 JDK 源码。