前言
这个问题是一年多前遇到的,当时也花了一些心思定位和解决。虽说最后的问题是通过简单地升级JDK版本解决的,没有改什么代码,但是也在这个过程中学到了很多东西。最近花了些时间好好梳理了一下整个过程,帮助自己记录一下。
问题发现
有一个读写业务很多的Elasticsearch集群,平稳运行一段时间之后,突然出现了单个节点CPU异常升高的情况,集群分片和整体负载都是均衡的。这个现象比较奇怪。简单通过jstack查看堆栈后发现了一个奇怪的堆栈信息,如下(示例堆栈):
"http-nio-8080-exec-9" #209 daemon prio=5 os_prio=0 cpu=15490900.00 tid=0x00007f470434c800 nid=0x58f2 / 22770 pthread-id=139914765780736 runnable java.lang.Thread.State: RUNNABLE
at java.lang.ThreadLocal$ThreadLocalMap.getEntryAfterMiss(Ljava/lang/ThreadLocal;ILjava/lang/ThreadLocal$ThreadLocalMap$Entry;)Ljava/lang/ThreadLocal$ThreadLocalMap$Entry;(ThreadLocal.java:480)
at java.lang.ThreadLocal$ThreadLocalMap.getEntry(Ljava/lang/ThreadLocal;)Ljava/lang/ThreadLocal$ThreadLocalMap$Entry;(ThreadLocal.java:455)
at java.lang.ThreadLocal$ThreadLocalMap.access$000(Ljava/lang/ThreadLocal$ThreadLocalMap;Ljava/lang/ThreadLocal;)Ljava/lang/ThreadLocal$ThreadLocalMap$Entry;(ThreadLocal.java:327)
at java.lang.ThreadLocal.get()Ljava/lang/Object;(ThreadLocal.java:163)
at java.util.concurrent.locks.ReentrantReadWriteLock$Sync.tryAcquireShared(I)I(ReentrantReadWriteLock.java:514)
at java.util.concurrent.locks.AbstractQueuedSynchronizer.acquireShared(I)V(AbstractQueuedSynchronizer.java:1282)
at java.util.concurrent.locks.ReentrantReadWriteLock$ReadLock.lock()V(ReentrantReadWriteLock.java:760)
at net.sf.ehcache.concurrent.ReadWriteLockSync.lock(Lnet/sf/ehcache/concurrent/LockType;)V(ReadWriteLockSync.java:50)
at net.sf.ehcache.constructs.blocking.BlockingCache.acquiredLockForKey(Ljava/lang/Object;Lnet/sf/ehcache/concurrent/Sync;Lnet/sf/ehcache/concurrent/LockType;)V(BlockingCache.java:196)
at net.sf.ehcache.constructs.blocking.BlockingCache.get(Ljava/lang/Object;)Lnet/sf/ehcache/Element;(BlockingCache.java:158)
at com.atlassian.cache.ehcache.LoadingCache.get(Ljava/lang/Object;)Lnet/sf/ehcache/Element;(LoadingCache.java:79)
at com.atlassian.cache.ehcache.DelegatingCache.get(Ljava/lang/Object;)Ljava/lang/Object;(DelegatingCache.java:108)
at com.atlassian.jira.cache.DeferredReplicationCache.get(Ljava/lang/Object;)Ljava/lang/Object;(DeferredReplicationCache.java:48)
at com.atlassian.jira.permission.DefaultPermissionSchemeManager.getPermissionSchemeEntries(JLcom/atlassian/jira/security/plugin/ProjectPermissionKey;)Ljava/util/Collection;(DefaultPermissionSchemeManager.java:293)
类似的堆栈出现在多个线程中,说明是ThreadLocal中的getEntryAfterMiss方法运行比较慢。
ThreadLocal
之前我有一篇关于es线程池的文章简单提到过ThreadLocal,这里再做一下简单的原理介绍,方便后面的问题分析。
ThreadLocal可以用来共享线程级别的临时变量,在同一个线程中set一个值后,可以在同一个线程中get到这个值,不需要通过方法来传递。在Web项目中用的比较多,一般情况下一个请求都是同一个线程来处理的,用ThreadLocal来保存用户信息,可以实现跨多个方法共享这部分信息,十分方便。
这里是一个简单的示意图:
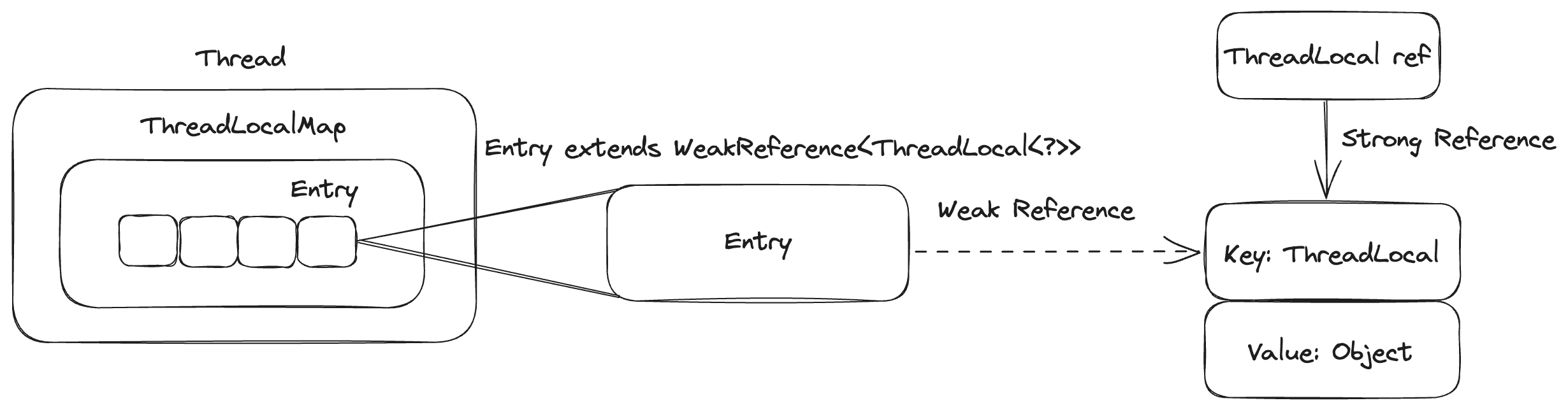
最外面是Thread实例,Thread实例中包含着ThreadLocalMap这样一个map实例,ThreadLocalMap实例中包含着Entry组成的数组,其中Entry实现了WeakReference这个弱引用抽象类:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
每个Entry可以看成一个k-v对,其中key就是ThreadLocal实例,value是ThreadLocal里面存储的内容。可以看到,Entry只持有了ThreadLocal的弱引用,外部的其他引用是强引用。这样设计的好处是,只要外部的引用不再持有了,ThreadLocal可以被GC回收掉了(当一个实例只有弱引用时,就能被垃圾收集器回收释放),这样可以防止出现内存泄露。
这里需要注意,当ThreadLocal可以被回收时,Entry和里面的Value是不能被回收的,因为还存在一个Thread -> ThreadLocalMap -> Entry -> Value的强引用没有释放,Entry和Value的释放是在replaceStaleEntry方法中做的,在ThreadLocal的set方法中发现了被回收ThreadLocal对应的Entry时就将对应的Entry和Value释放掉:
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
线性探测法
继续看堆栈,可以看到具体是getEntryAfterMiss方法出现了问题,代码如下:
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
ThreadLocal<?> k = e.get();
if (k == key)
return e;
if (k == null)
expungeStaleEntry(i);
else
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
上文说到,存储具体ThreadLocal的map是由Entry数组组成的,再结合这段代码,可以看出来ThreadLocalMap和Java的HashMap相比用来解决hash冲突的方式不同,HashMap用了拉链法+红黑树,而ThreadLocalMap则用了非常简单的线性探测法。
线性探测法具体做法是:
- set:算出key的hashcode,然后通过取余得到一个数组中的位置,然后尝试写到该位置,如果被占就不停地向后移位直到找到第一个空位再写入。
- get:算出key的hashcode,然后通过取余得到一个数组中的位置,然后尝试读取该位置的key,跟需要拿的key做比较,如果不同则不停地向后移位直到找到对应的值。
可以看到这段代码就是线性探测法get出现不同(miss)的流程。
那么这个方法出现cpu占用高的情况,只能说明线性探测的冲突太多,导致每拿一个值都循环了很久才找到。但是由于上面说到的Entry实际上是一个弱引用,所以正常情况下不再被使用的ThreadLocal都能被GC回收掉,Entry也能通过replaceStaleEntry释放,这样Entry就会空出来,根本不会出现不停增长的情况。
通过jmap -histo命令大概查看下实例个数可以发现,java.lang.ThreadLocal$ThreadLocalMap$Entry有几百万之多,在这种情况下,线性探测遍历过程的cpu占用高就可以理解了。
将jmap加上live选项可以触发full gc,使用jmap -histo:live命令触发了一次full gc,问题果然解决了。但是这只是一种规避手段,运行一段时间这个问题一定还会再出现的。
不过也不是一无所获,通过上面的分析可以得到一个结论:在这种场景下,垃圾回收没有按照预期结果回收ThreadLocal。
CMS、G1
实际上这个问题还有一个可以利用的信息,那就是线上的使用CMS收集器的集群没有出现过类似问题,只有使用G1收集器的集群出现了。因此尝试将问题集群的G1替换成CMS,观察一段时间后发现问题果然没有再出现。
G1吞吐量更高,在处理大内存方面也更优秀。并且G1在JDK9之后是默认的垃圾收集器,CMS在JDK14之后直接被移除了。将垃圾收集器换回CMS也不是长久之计。
这就需要分析一下CMS和G1到底哪点不同才会导致这个问题了。当时分析到这里完全没了思路,好在谷歌了一下,发现曾经有人遇到过这个问题,并且做了一些分析
节选一段:
With G1 (and C4, and likely Shenandoah and ZGC), with the current ThreadLocal implementation, the “means “until the next GC detects that the ThreadLocal is no longer reachable” meaning gets compounded by the fact that collisions in the map will actually prevent otherwise-unreachable ThreadLocal instances from becoming unreachable. As long as get() calls for other (chain colliding) ThreadLocals are actively performed on any thread, where “actively” means “more than once during a mark cycle”, the weakrefs from the colliding entries get strengthened during the mark, preventing the colliding ThreadLocal instances from dying in the given GC cycle. Stop-the-world newgen provides a bit of a filter for short-lived-enough ThreadLocals for G1, but for ThreadLocals with mid-term lifecycles (which will naturally occur as queues in a work system as described above grow under load), or without such a STW newgen (which none of the newer collectors have or want to have have), this situation leads to explosive ThreadLocal map growth under high-enough throughout situations.
总结一下,就是ThreadLocal中get()的调用会使得标记阶段ThreadLocal实例的引用被加强了,导致不能被GC回收掉。
这段说明的作者也是个大牛,名叫Gil Tene,是Azul的CTO。这个公司就是专门做JVM相关产品的,很厉害。
这里所说的get()就是WeakReference的get()方法,是不是有点眼熟,问题堆栈的那个方法里面就有:
ThreadLocal<?> k = e.get();
这是在循环里面做的,等于说是出现冲突之后,通过线性探测法拿值的过程中会建立新的引用,导致ThreadLocal实例不能被正常gc回收。
这个解释看起来很有道理,但是还是不能解释为什么CMS不会出现这个问题。不过分析的方向是有了,看下CMS和G1在标记阶段的差别就好了。
三色标记法
垃圾收集器的标记使用的是三色标记法,分别为黑色、灰色和白色。含义参考下图:
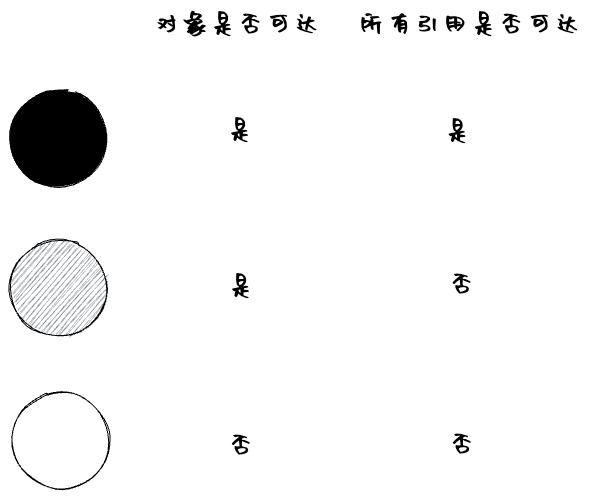
在标记阶段,GC线程从GC Roots开始进行可达性分析,类似一个树结构不停的向叶子结点遍历,在遍历的过程中将实例染色。完成标记之后,所有可达的实例都会被标记为黑色,其他的白色实例均为不可达实例,这种实例就会被GC掉。
大部分的垃圾收集器为了减少GC停顿,主要的标记阶段是和用户线程运行并发的,也就是所谓的并发标记。但是用户线程肯定会增加或者删除引用关系,垃圾收集器是怎么保证标记不会出问题呢。这其中包含了多标和漏标:多标不影响实际的结果,但是漏标就会导致明明可达的对象被回收掉了,这就会导致很严重的bug。
其实漏标需要同时满足两个条件,对于一个白色节点C来说:
- 新增一个黑色节点A到白色节点C的引用
- 所有灰色节点(比如说B)到白色节点C的引用都被释放了
这个画一个示意图:
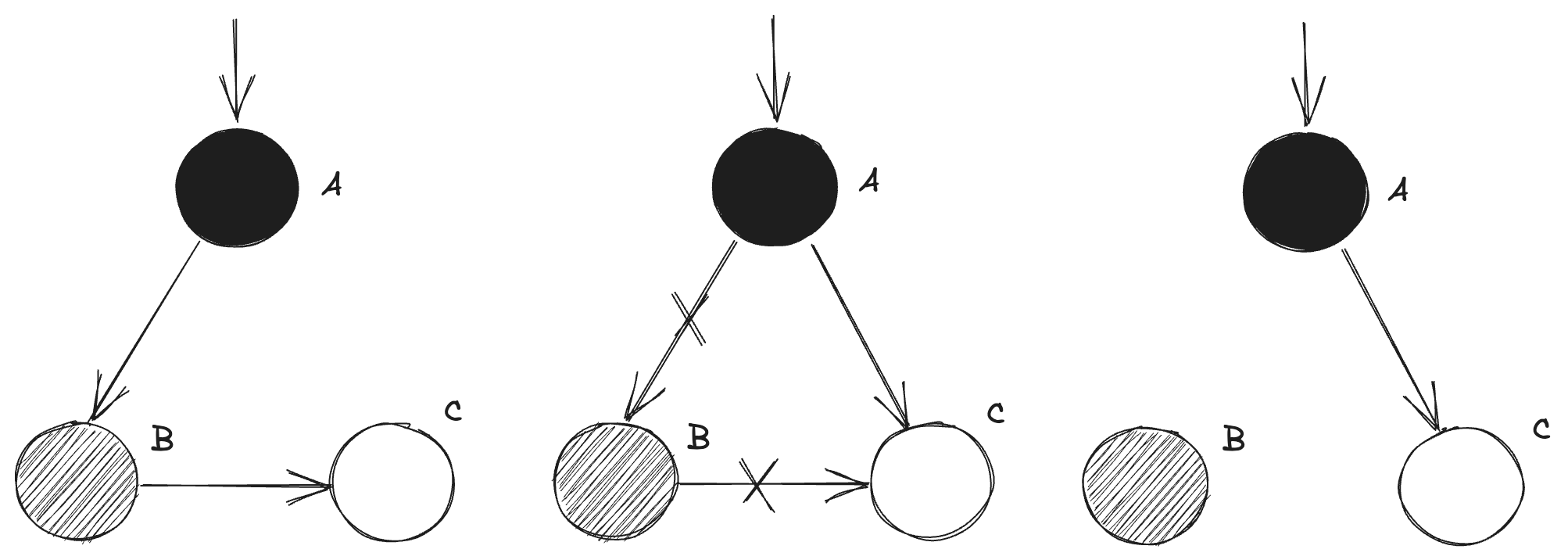
可以发现经过这两个条件影响后,明明被B引用的C节点最后变得被A引用了,但是A是黑色节点,可达性分析已经结束,所以C节点最终会被错误地回收。
要解决这个问题,破坏上面的任意一个条件就可以。破坏条件一就对应着CMS的增量更新算法(Incremental-Update):当新增黑色节点到白色节点引用时,将这个黑色节点标记为灰色,下一次标记时就能找到白色节点;破坏条件二就对应着G1等新垃圾收集算法的起始快照算法(Snapshot-At-The-Beginning, SATB):当所有灰色节点到白色节点的引用被释放时,将白色节点记录下来,直接记录为存活节点。
由于互联网(尤其是中文互联网)上很难找到关于GC算法靠谱的信息源,这段分析参考了这本书《Advanced Design and Implementation of Virtual Machine》16.2的内容,作者主页在这里。作者曾经是Apache Harmony项目的committer,所以这本书的内容是比较靠谱的。建议看英文版,中文版机翻痕迹较重。
回到最开始的那段代码,在解决线性探测法导致的冲突时,ThreadLocal实例的引用在循环中不停地被建立和释放。局部变量k相当于黑色节点A,ThreadLocal实例相当于白色节点C。在CMS中,局部变量k在并发标记结束时被标记为灰色,最终标记中也最多只会引用到一个ThreadLocal实例。但在G1中就不一样了,在并发标记中多个ThreadLocal的实例引用被释放,这些实例全部被标记为存活状态,因而大量ThreadLocal实例变成了浮动垃圾。最终ThreadLocal数量爆炸导致问题出现。
解决方案
分析了那么多,看上去这个问题好像是挺难解决的。但是只需要仔细搜索一下就能找到一个JDK的bug单。具体内容就是上面分析的那个问题。解决方案也很简单,增加一个新的方法,不再新增一个会导致GC问题的引用,而是直接在JVM内部判断引用是不是相同。原来的get方法也加上了一段注释说明:
/**
* Returns this reference object's referent. If this reference object has
* been cleared, either by the program or by the garbage collector, then
* this method returns {@code null}.
*
* @apiNote
* This method returns a strong reference to the referent. This may cause
* the garbage collector to treat it as strongly reachable until some later
* collection cycle. The {@link #refersTo(Object) refersTo} method can be
* used to avoid such strengthening when testing whether some object is
* the referent of a reference object; that is, use {@code ref.refersTo(obj)}
* rather than {@code ref.get() == obj}.
*
* @return The object to which this reference refers, or
* {@code null} if this reference object has been cleared
* @see #refersTo
*/
@IntrinsicCandidate
public T get() {
return this.referent;
}
在我的推动下,新的ES版本全都换上了JDK17,这个问题也再也没有出现过了。
总结
这个问题当初分析的时候就花了挺长时间,这次梳理为了尽量准确又查了很多资料。JVM/GC这一整个系统是真的很复杂,理解一些基本概念不难,但是真的需要刨根问底的时候,这里面的细节多得可怕。