数据库大神 Andy Pavlo 一直坚持着一个观点:不要在数据库系统中使用 MMAP,对于这个观点我不是太理解。最近闲逛数据库大神 Andy Pavlo 的 twitter 时发现,他和他的学生竟然发了一篇论文来论证这个结论,这我不得抓紧拜读一下。
论文不长,并且比较好理解。本文就基于这篇论文写一下论文笔记,加深自己理解的同时也可以方便读者。
问题引出
作者引出了两种数据库系统中对于文件 I/O 管理的选择:
- 开发者自己实现 buffer pool 来管理文件 I/O 读入内存的数据
- 使用 Linux 操作系统实现的 MMAP 系统调用将文件直接映射到用户地址空间,并且利用对开发者透明的 page cache 来实现页面的换入换出
由于第二种方案,开发者不需要手动管理内存,实现起来简单,因此很多数据库系统曾经使用 MMAP 来代替 buffer pool,但是由于一些问题导致它们最终弃用了 MMAP(这一点也是论文的一个重要的论据),改为自己管理文件 I/O。
本论文通过理论的引入和实验的结论证明 MMAP 不适合用在数据库系统中。
理论介绍
论文首先介绍了程序是如何通过 MMAP 系统调用访问到文件,结合着配图,原理十分清晰。
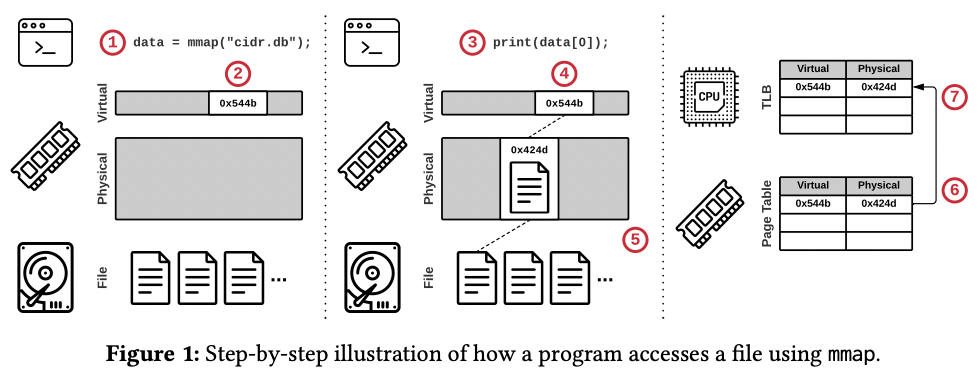
- 程序调用 MMAP 返回了指向文件内容的指针
- 操作系统保留了一部分虚拟地址空间,但是并没有开始加载文件
- 程序开始使用指针获取文件的内容
- 操作系统尝试在物理内存获取内存页
- 由于内存页此时不存在,因此触发了页错误,开始从物理存储将第 3 步获取的那部分内容加载到物理内存页中
- 操作系统将虚拟地址映射到物理地址的页表项(Page Table Entry)加入到页表中
- 上述操作使用的 CPU 核心会将页表项加载到页表缓存(TLB)中
然后介绍了 MMAP 和其相关的几个 API
- mmap:介绍了 MAP_SHARED 和 MAP_PRIVATE 在可见性上的区别
- madvise:介绍了 MADV_NORMAL,MADV_RANDOM 和 MADV_SEQUENTIAL 在预读上的区别
- mlock:可以尝试性的锁住内存中的页面,一定程度上防止被写回存储。(然而并不是确定性的锁住)
- msync:将页面从内存写回存储的接口
论文列举了几种曾经使用过 MMAP 的数据库例子:

问题陈述
论文列举了三点关于使用 MMAP 可能引起的问题:
问题一 事务安全
由于 MMAP 中页面写回存储的时机不受程序控制,因此当 commit 还没有发生时,可能会有一部分脏页面已经写回存储了。此时原子性就会失效,在过程中的查询会看到中间状态。
为了解决事务安全问题,有以下三个解决方式:
- 操作系统写时复制(copy-on-write):使用 MAP_PRIVATE 标识位创建一个独立的写空间(物理内存复制),写操作在这个写空间执行,读操作仍读取原来的空间。同时使用 WAL(write-ahead log)来保证写入操作被持久化。事务提交之后将写空间新增的内容复制到读空间。
这里存在一个疑问,原文是这样表述的: When a transaction commits, the DBMS flushes the corresponding WAL records to secondary storage and uses a separate background thread to apply the committed changes to the primary copy. 我的理解是:持久化的不应该是 WAL 的记录,而应该是写空间的 msync,只有 msync 意外中断的时候,才需要从 WAL 恢复。这个理解有可能是错误的,等我之后理解了再来更新吧。
- 用户空间写时复制(copy-on-write):类似操作系统写时复制,不过写空间在用户空间开辟,同样写入 WAL 保证持久性。事务提交后,从用户空间写回读空间。
这里提到了: Since copying an entire page is wasteful for small changes, some DBMSs support applying WAL records directly to the mmap-backed memory. 特殊提到了一些数据库支持 WAL 直接写入,说明不是大多数数据库的行为,也验证了上面疑问中我的理解可能是对的。
- 影子分页:影子分页类似第一种方法,不过没有 WAL 的参与,而是直接出来两份分页,一份只读的,另一份可写,事务提交就是在可写页表做 msync 之后再让只读页表可以读到最新的页。
问题二 I/O 停顿
作者主要提到的就是,由于 MMAP 将文件加载到内存的过程是操作系统控制的,所以无法保证将要查询的页面在内存中,这时就会出现 page cache 的换入换出,导致 I/O 停顿。
这一点比较好理解,毕竟操作系统使用 page cache 并没有针对数据库场景进行特别的优化,那么很有可能在页面将要被使用的时候,由于 page cache 不足要使用的页面被换出,从而影响性能。
问题三 错误处理
首先是 MMAP 对文件内容的校验要以单个页面为单位,不能基于多个页面来做,因为有可能要使用的页面会被换出。
另外,对于一些使用内存不安全语言写的数据库系统(感觉大部分都是用内存不安全的 C++写的),指针错误可能导致页面问题。使用 buffer pool 可以通过写入前的检查规避这个问题,但是 MMAP 会默默将错误的页面写到存储中。
还有,MMAP 要应对的系统调用会出现的 SIGBUS 信号报错,相比之下使用其他 I/O 方式的 buffer pool 就能比较轻松的处理 I/O 错误。
问题四 性能问题
其实讲到这里,作者才算是“图穷匕见”,因为这片论文后面的实验主要想证明的就是这一点。
业界里面大家普遍认为 MMAP 比传统 read/write 更快,这主要基于以下两点原因:
- 负责文件映射操作,并且处理 page fault 的是内核,而不是应用程序
- MMAP 帮助避免了用户空间中的额外的复制操作,相应的也减少了内存的占用
接下来作者提出了他们的发现:MMAP 相对于传统 read/write I/O 在目前高带宽的存储设备上是更差的。并指出了三点原因:
- 页表竞争
这一点没有太理解,下面的解释是: Finally, the OS must synchronize the page table, which becomes highly contended with many concurrent threads. 但是我理解线程切换应该不需要切换页表
- 单线程的页面换出: 页面换出是单线程的(使用 kswapd),这点与 CPU 相关
- TLB shootdowns 当一个页面失效时,每个核心的 TLB 都需要一次中断来做刷新操作,这个操作可能会消耗几千个时钟周期,是非常耗时的。
实验说明
这里的实验就不详细写了,有兴趣的可以去看原文。作者主要分了随机读写和顺序读写两个实验来做,证明了直接 I/O 比 MMAP 有几倍到几十倍的速度优势。
总结
Andy 和他的学生无疑是 buffer pool 的拥趸,他们代表着学术界,不建议在数据库系统中使用 MMAP。但我们看一下工业界,还是有很多数据库系统在使用 MMAP。这可能也是这两类人的立场不同导致的吧。对于学术界来说,性能是最重要的,成本并不是需要考虑的重点。而工业界则是追求在能接受的成本下实现最好的性能。 所以说,计算机科学领域没有银弹,就像 I/O 方式的选择一样,从传统的 read/write 到 mmap,再到直接 I/O 和异步 I/O,每一种方式都有人在使用,并不是说异步 I/O 性能好就能吸引所有人使用,毕竟要受到成本和其他因素的限制。 不过呢,还是希望工业界能够在技术追求上内卷起来,毕竟谁不愿意搞出来一个很叼的东西呢。感觉 ScyllaDB 就是个不错的例子,也希望他们能火起来吧。
RavenDB 的 CEO 写了一篇博客回应了这篇论文,这也算是工业界的反击吧,有趣有趣。